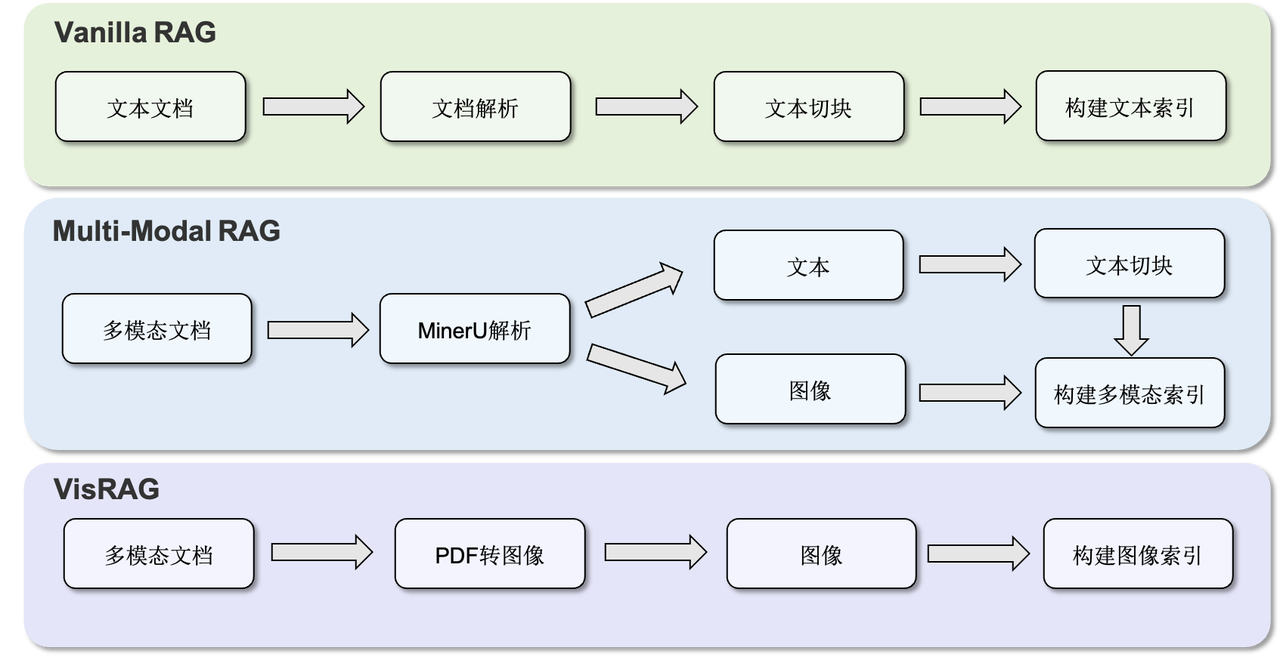
UltraRAG 3.0:告别黑盒,推理逻辑全透明


“验证算法原型只需一周,构建可用系统却耗时数月。” 这句看似调侃的“吐槽”,却是每一位算法工程师不得不面对的真实困境。
今天,清华大学 THUNLP 实验室、东北大学 NEUIR 实验室、OpenBMB 、面壁智能与 AI9Stars 联合发布 UltraRAG 3.0 ,针对上述痛点,为科研工作者与开发者打造更懂开发者的技术框架,具备 3 大核心优势:
-
从逻辑到原型的一键跨越,让算法工程师回归“算法”:提供“所见即所得”的 Pipeline 构建器,自动接管繁琐的界面封装。只需专注于逻辑编排,即可让静态代码即刻变身为可交互的演示系统。
-
全链路白盒化,推理轨迹的“像素级”可视化: 打造“透明化”的推理验证窗口,实时呈现模型在复杂长链条任务中的每一次循环、分支与决策细节。
-
内置智能开发助手,你的“交互式开发指南”: 内嵌懂框架的 AI 助手,通过自然语言交互辅助生成 Pipeline 配置与优化 Prompt,大幅降低上手门槛。
逻辑即应用——从编排到交互的「零距离」体验
让算法的终点不再是冷冰冰的控制台日志。UltraRAG 3.0 通过自动化处理繁琐的界面封装与参数对接,确保在逻辑编排完成的一刻,便已同步生成了可交互的演示界面:
- 配置即应用:只需定义 Pipeline 的 YAML 配置文件,框架即可将其自动解析并转化为标准的交互式 Demo。
- 双模式构建器:为了平衡易用性与灵活性,我们打造了可视化与代码实时同步的构建引擎:
- 画布模式:通过 UI 组件,像搭积木一样直观组装 Loop(循环)、Branch(分支)等复杂逻辑。
- 代码模式:直接编辑 YAML 配置文件,画布视图实时渲染更新,满足开发者对参数微调的精准控制需求。
- 一键编译验证:构建完成后,点击顶部的 “Build” 按钮,系统自动执行逻辑自检与语法校验,并动态生成参数配置面板。参数就绪的瞬间,静态的算法逻辑即刻变身可交互的系统,真正实现“所写即所得,所得即所用”。
拒绝「黑盒」让复杂 RAG 的推理脉络清晰可见
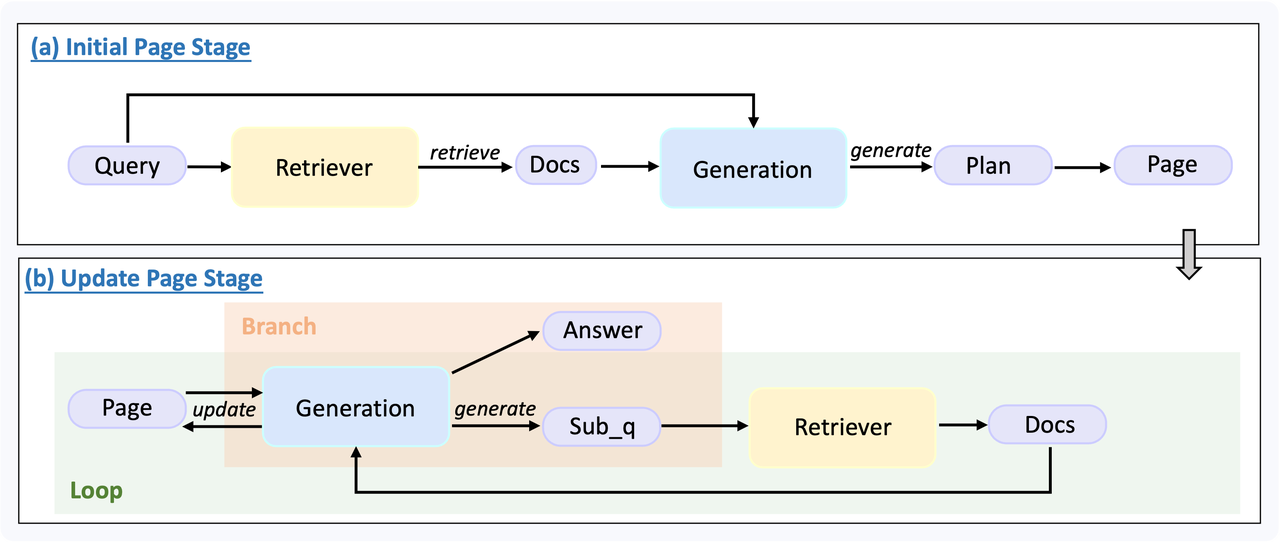
随着 RAG 技术从简单的单次检索向多轮动态决策演进,推理链路往往长达上百个 Step。在缺乏中间态监控的情况下,调试过程就如同在迷雾中从头再来,错误定位全靠“猜”。
UltraRAG 3.0 重新定义了 Chat 界面——它不仅是用户交互的入口,更是 逻辑验证的窗口。我们深知,对于开发者而言,知道“结果是什么”远远不够,看清“结果怎么来的”才是优化的关键。
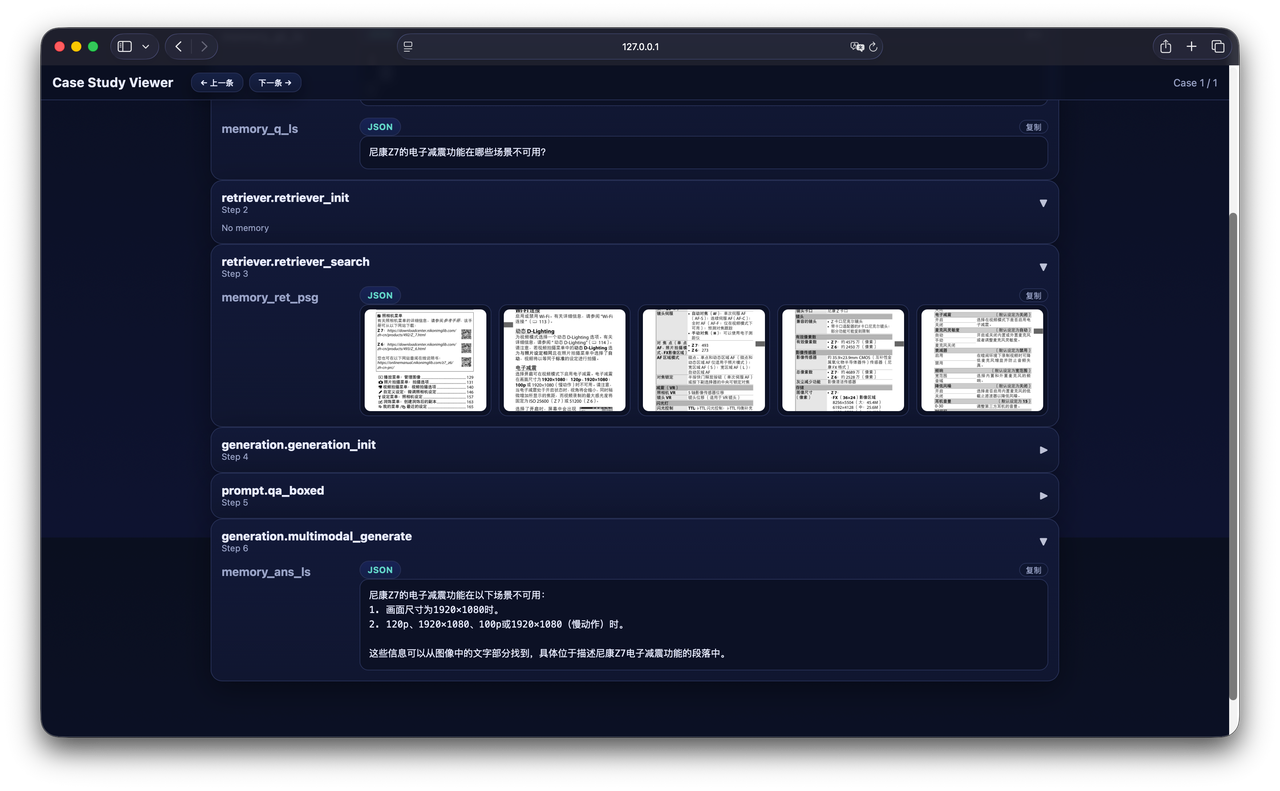
我们通过“Show Thinking”面板,对系统“思考”的全过程进行了像素级的实时可视化——从复杂的循环分支到具体的工具调用,所有中间状态均以结构化的形式流式呈现。即使是 DeepResearch 这样复杂的长流程任务,开发者也能实时掌握执行进度,让过程不再是漆黑的等待。当 Bad Case 出现时,开发者无需再后台翻找日志,只需在界面上直接比对检索切片与最终答案,快速判断问题是出在“数据层的噪声”还是“模型层的幻觉”,极大地缩短了优化迭代的周期。
这里选取了 AgentCPM-Report 工作流的两个典型场景来展示“白盒化”调试的实际效果:
解放定制开发的「框架桎梏」
想要尝试一个新的算法逻辑,往往需要深入框架底层,重写大量继承类。为了实现 10% 的核心算法创新,却不得不背负 90% 的框架学习成本。
UltraRAG 3.0 将整套开发文档与最佳实践内嵌到了框架自带的智能助手中。它或许无法像 Cursor 那样帮你写完整个项目,但它绝对是最懂 UltraRAG 的高效辅助工具。通过自然语言交互,它能帮你彻底抹平“阅读文档”与“编写配置”之间的认知阻力:
- 配置生成:你只管描述需求(例如:“我要一个带多路召回和重排序的流程”),助手即可自动生成标准的 Pipeline 结构草稿,只需微调即可直接使用。
- Prompt 调优:助手能根据当前任务上下文,提供针对性的 Prompt 优化建议,快速适配特定业务场景。
- 辅助理解:看不懂某个参数或逻辑?无需跳转浏览器翻阅官网文档,直接提问即可获得开发建议与代码示例,让编码过程不再中断。
实战演示:它能帮你做什么
我们在此展示了四个真实的交互场景,看看它是如何将自然语言转化为“可执行逻辑”的:
1. 结构调整:一句话修改 Pipeline
User:“请帮我修改当前的 Pipeline,增加一个引用(Citation)功能模块,以便对生成内容进行事实核查。”
2. 场景适配:针对性优化 Prompt
User: “我需要针对 法律场景 优化当前的 Prompt。请调整提示词,使其生成的回答在该领域的术语使用和逻辑推演上更加专业和准确。”
3. 配置调整:轻松修改底层参数
User: “我要切换生成后端的配置。请将生成模型后端改为 OpenAI,模型名更改为 qwen3-32b,API 服务部署在端口 65503 上。”
4. 自由调优:从概念到实现的捷径
User: “我想参考这篇论文:https://arxiv.org/pdf/2410.08821 (DeepNote),来重新设计我的 RAG 流程。请分析文章中的核心思想,并帮我搭建一套类似的 Pipeline 架构。”