UltraRAG 2.1:纵深知识接入,横跨多模态支持


在研究者构建知识库、搭建实验系统、评估实验结果的过程中,总会遇到相似的挑战:如何在一个统一框架中实现多模态检索与生成?如何高效接入多源知识?又如何让复杂的 RAG 实验更易搭建、更易复现?
UltraRAG 2.1 在这些科研挑战的背景下,进行了面向实际研究需求的全面升级。本次更新围绕 原生多模态支持、知识接入与语料构建自动化、统一构建与评估的 RAG 工作流 三大方向带来了核心增强:
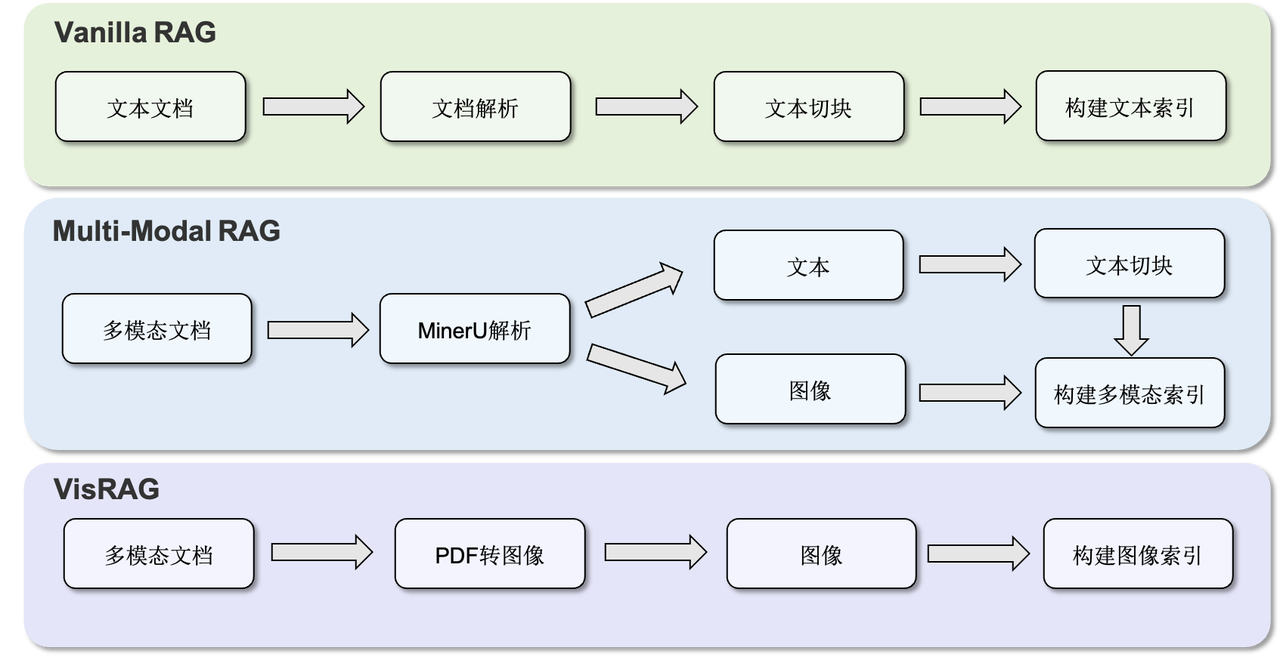
- 原生多模态支持:统一 Retriever、Generation 与 Evaluation 模块,全面支持多模态检索与生成;新增 VisRAG Pipeline,实现从本地 PDF 建库到多模态检索与生成的完整闭环。
- 知识接入与语料构建自动化:支持多格式文档解析与分块建库,无缝集成 MinerU,轻松构建个人化知识库。
- 统一构建与评估的 RAG 工作流:适配多种检索与生成推理引擎,提供标准化的评估体系,支持全链路可视化分析,实现从模型调用到结果验证的统一流程。
原生多模态支持
过去,多模态 RAG 往往需要依赖多套独立工具:文本任务与视觉任务分属不同流程,研究者需在特征提取、检索、生成和评估工具间来回切换,接口不统一、复现困难。
UltraRAG 2.1 对多模态 RAG 流程进行了系统化整合。所有核心 Server——Retriever、Generation 与 Evaluation——均已原生支持多模态任务,可灵活接入各种视觉、文本、或跨模态模型。研究者可在统一框架内自由编排属于自己的多模态 pipeline,无论是文档问答、图文检索,还是跨模态生成,都能以最小代价实现端到端联通。此外,框架内置的 Benchmark 覆盖视觉问答等多种任务,并提供统一的评估体系,方便研究者快速开展和对比多模态实验。
在此基础上,UltraRAG 2.1 引入 VisRAG Pipeline,实现从本地 PDF 建库到多模态检索与生成的完整闭环。该功能基于论文《VisRAG: Vision-based Retrieval-augmented Generation on Multi-modality Documents》的研究成果,论文提出了一个面向多模态文档的视觉增强检索生成框架,通过将文档图像信息(如图表、公式、版面结构)与文本内容联合建模,显著提升了模型在复杂科学文档中的内容理解与问答能力。UltraRAG 将这一方法集成,使研究者能够直接在真实 PDF 文档场景中复现 VisRAG 的实验过程,并进一步扩展多模态检索生成的研究与应用。
知识接入与语料构建自动化
在 RAG 开发过程中,面对不同来源的资料,开发者需要反复解析、清洗、分块。结果是,RAG 的构建过程往往被琐碎的工程细节拖慢,科研创新的空间反而被压缩。
UltraRAG 2.1 的 Corpus Server 让这一切变得简单。用户无需编写复杂脚本,就能一次性导入来自不同来源的语料——无论是 word 文档还是电子书与网页存档,都能被自动解析为统一的文本格式。在 PDF 解析方面,UltraRAG 无缝集成 MinerU,能够精确识别复杂版面与多栏结构,实现高保真文本还原。对于图文混排文件,还支持将 PDF 按页转换为图像,让视觉布局也能成为知识的一部分。在分块策略上,Corpus Server 提供了多粒度选择:支持词元级、句子级与自定义规则,既能精细控制语义边界,又能自然适配 Markdown 等结构化文本。
通过这一整套自动化流程,Corpus Server 将语料导入、解析与分块过程模块化,减少了手工脚本与格式适配工作,使知识库构建可以直接融入 RAG pipeline 的标准化流程中。
统一构建与评估的 RAG 工作流
“切块、索引、检索、生成、评估,每一步都要用不同的脚本,太繁琐了!” “每改一次参数、换一个模型,是否又要重搭整条 pipeline?” “当实验终于跑通后,评估结果又该怎样保持一致与可比?”
这些问题几乎是每个 RAG 研究者都经历过的烦恼。现有框架对检索、模型接入、评估的支持往往零散且不兼容,研究者不得不在不同工具之间反复切换,每一次修改都可能引发整条实验链路的重建。UltraRAG 2.1 的目标,就是让复杂的流程重新变得清晰而统一。
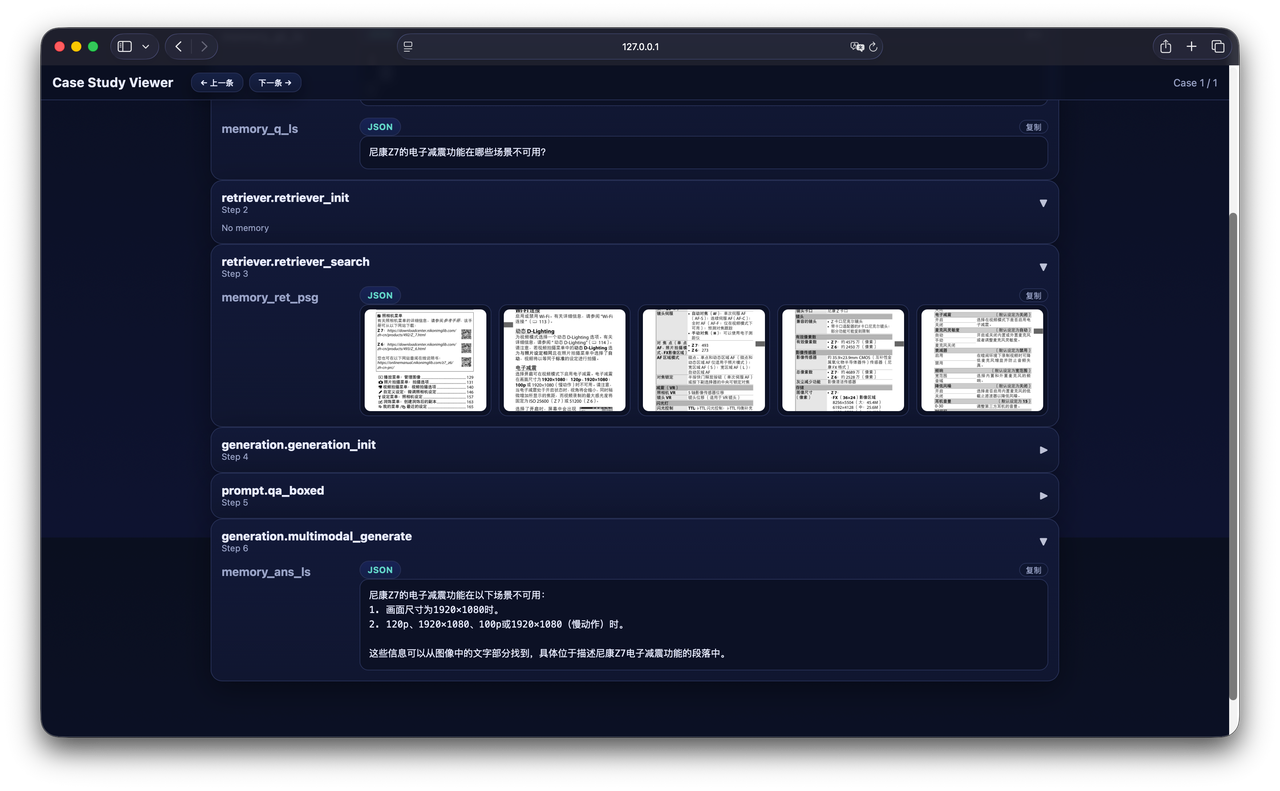
在检索层面,框架支持稀疏、稠密、混合与多模态检索,并兼容 Infinity、Sentence-Transformers、OpenAI 等多种后端引擎,研究者可以自由组合检索策略与模型,实现灵活的 pipeline 设计。在模型生成部分,UltraRAG 2.1 同时支持 vLLM 离线推理 与 Hugging Face 本地调试,并保持与 OpenAI 接口 完全兼容,使模型切换与部署无需修改代码。在评估环节,UltraRAG 构建了统一的 Evaluation Server,既能对生成结果计算 ACC、ROUGE 等指标,又支持对检索结果进行 TREC 评估与显著性分析。配合可视化的 Case Study UI,研究者可以直观地比较不同模型与策略的表现,让“调试”真正变成“理解”。
此外,UltraRAG 通过 YAML 配置驱动的工作流机制,实现了从数据导入到检索、生成与评估的全链路串联,研究者只需编写少量配置文件,即可快速定义和复现实验流程。