UltraRAG 2.0: Minimal Code, Maximum Innovation



Retrieval-Augmented Generation (RAG) systems are evolving from the early simple "retrieval + generation" concatenation toward complex knowledge systems integrating adaptive knowledge organization, multi-round reasoning, and dynamic retrieval (typical examples include DeepResearch and Search-o1). However, this increase in complexity creates high engineering implementation costs for developers when reproducing methods and rapidly iterating on new ideas.
To address this pain point, Tsinghua University's THUNLP Lab, Northeastern University's NEUIR Lab, OpenBMB, and AI9Stars jointly launch UltraRAG 2.0 (UR-2.0) — the first RAG framework designed with Model Context Protocol (MCP) architecture. This design allows researchers to declare complex logic such as serial execution, loops, and conditional branches directly by writing YAML files, enabling rapid implementation of multi-stage reasoning systems with minimal code.
UltraRAG 2.0 highlights at a glance:
-
🧩 Component-based Encapsulation: Encapsulates core RAG components as standardized independent MCP Servers;
-
🔌 Flexible Invocation & Extension: Provides function-level Tool interfaces supporting flexible invocation and extension of capabilities;
-
🪄 Lightweight Pipeline Orchestration: Leverages MCP Client to establish streamlined top-down pipeline construction; Compared to traditional frameworks, UltraRAG 2.0 significantly lowers the technical threshold and learning cost of complex RAG systems, allowing researchers to invest more energy in experimental design and algorithm innovation rather than getting bogged down in lengthy engineering implementation.
Simplifying Complexity — Only 5% Code for Low-Barrier Reproduction
The value of "simplicity" is particularly intuitive in practice. Taking IRCoT (https://arxiv.org/abs/2212.10509), a classic method, as an example — it relies on CoT generated by the model for multi-round retrieval until producing the final answer, making the overall process quite complex.
In the official implementation, the Pipeline portion alone requires nearly 900 lines of handwritten logic; even using other RAG frameworks still requires over 110 lines of code. In contrast, UltraRAG 2.0 achieves equivalent functionality with only about 50 lines of code. More notably, approximately half of that is YAML pseudo-code for orchestration, dramatically lowering the development threshold and implementation cost.
Simple Yet Extraordinary — Dozens of Lines of Code for High-Performance RAG Systems
For UltraRAG 2.0, "simplicity" does not mean limited functionality. Leveraging the MCP architecture and flexible YAML pipeline definitions, UltraRAG 2.0 provides researchers with a high-performance, extensible experimental platform. Researchers can build multi-stage reasoning systems similar to DeepResearch in a very short time, supporting advanced capabilities like dynamic retrieval, conditional judgment, and multi-round interaction.
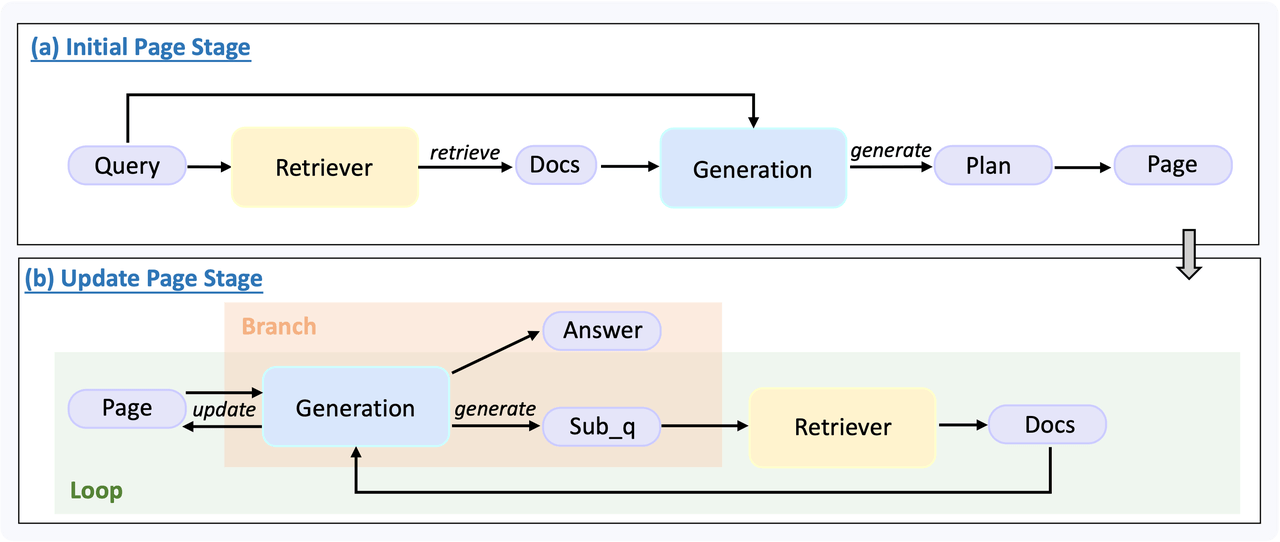
In the example, we concatenate Retriever, Generation, Router and other modules through YAML to build a reasoning pipeline with both loops and conditional branches, implementing key steps like Plan Generation → Knowledge Organization → Sub-question Generation — all in under 100 lines of code.
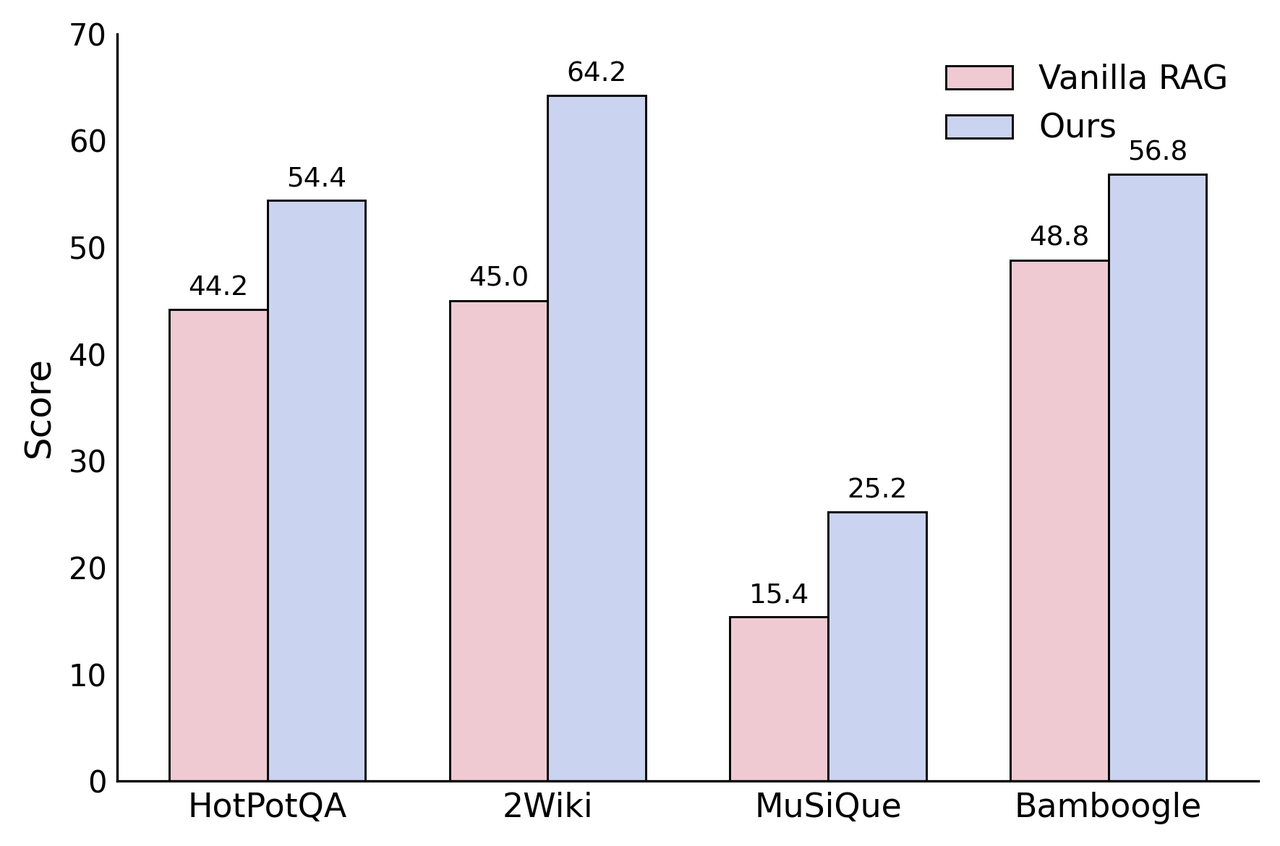
In terms of performance, this system achieves a ~12% performance improvement over Vanilla RAG on complex multi-hop questions, fully validating UltraRAG 2.0's potential in rapidly building complex reasoning systems.
UltraRAG 2.0 makes building complex reasoning systems truly low-code, high-performance, and production-ready. Users can not only achieve performance improvements in research tasks but also quickly deploy in industry applications such as intelligent customer service, educational tutoring, and medical QA, delivering more reliable knowledge-enhanced answers.
MCP Architecture and Native Pipeline Control
Across different RAG systems, core capabilities like retrieval and generation are functionally highly similar, but due to varying developer implementation strategies, modules often lack unified interfaces and are difficult to reuse across projects. Model Context Protocol (MCP), as an open protocol, standardizes the way context is provided for Large Language Models (LLMs) and adopts a Client-Server architecture, enabling Server components developed following this protocol to be seamlessly reused across different systems.
Inspired by this, UltraRAG 2.0 abstracts and encapsulates core RAG functions such as retrieval, generation, and evaluation as mutually independent MCP Servers based on the MCP architecture, with invocation through standardized function-level Tool interfaces. This design ensures flexibility in module capability extension while allowing new modules to be integrated in a "hot-pluggable" manner without invasive modifications to the overall codebase. In research scenarios, this architecture enables researchers to rapidly adapt to new models or algorithms with minimal code while maintaining the stability and consistency of the overall system.
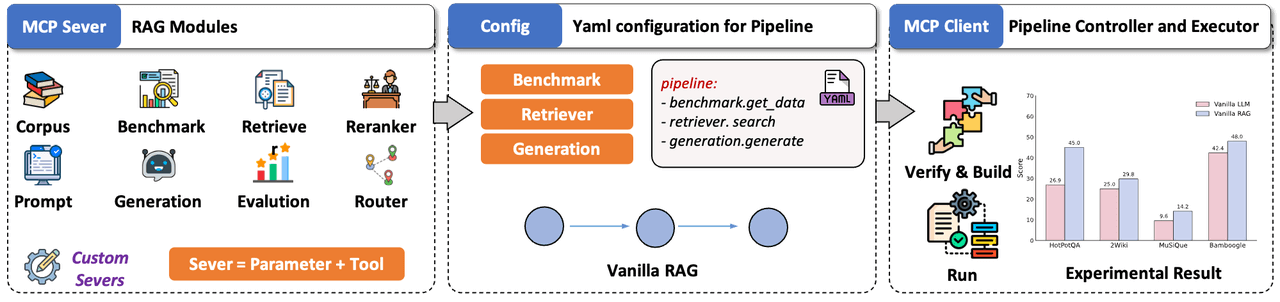
The development of complex RAG reasoning frameworks is significantly challenging, and the reason UltraRAG 2.0 can support complex system construction under low-code conditions lies in its underlying native support for multi-structure Pipeline flow control. Whether serial, loop, or conditional branch, all control logic can be defined and scheduled at the YAML level, covering various process expression methods required by complex reasoning tasks. During actual execution, reasoning process scheduling is performed by the built-in Client, whose logic is entirely described by external Pipeline YAML scripts written by users, achieving decoupling from the underlying implementation. Developers can invoke instructions like loop and step like programming language keywords, rapidly building multi-stage reasoning pipelines in a declarative manner.
By deeply integrating MCP architecture with native process control, UltraRAG 2.0 makes building complex RAG systems as natural and efficient as "orchestrating workflows." Additionally, the framework includes 17 mainstream benchmark tasks and multiple high-quality baselines, combined with a unified evaluation system and knowledge base support, further improving system development efficiency and experimental reproducibility.