UltraRAG 2.1: Deep Knowledge Integration, Cross-Modal Support


In the process of building knowledge bases, setting up experimental systems, and evaluating results, researchers always encounter similar challenges: How to achieve multimodal retrieval and generation within a unified framework? How to efficiently integrate multi-source knowledge? And how to make complex RAG experiments easier to build and reproduce?
UltraRAG 2.1 addresses these research challenges with comprehensive upgrades focused on practical needs. This update brings core enhancements in three directions: native multimodal support, automated knowledge integration and corpus construction, and unified build-and-evaluate RAG workflows:
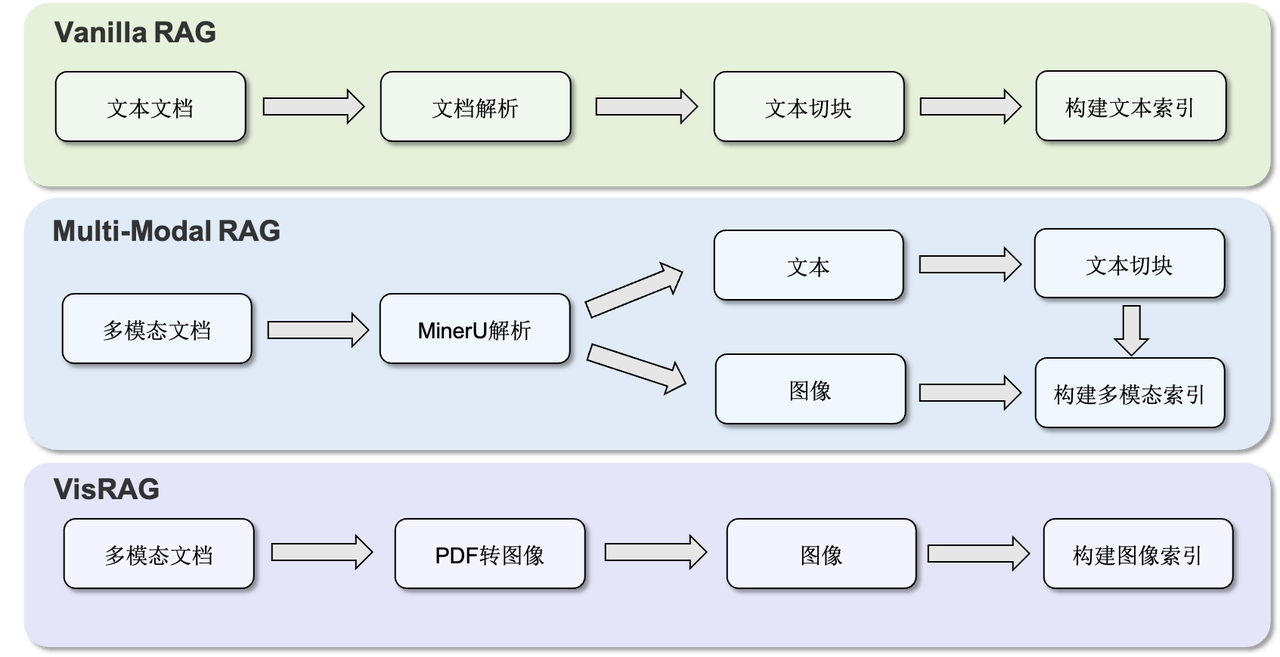
- Native Multimodal Support: Unified Retriever, Generation, and Evaluation modules with full multimodal retrieval and generation support; new VisRAG Pipeline enabling a complete closed-loop from local PDF indexing to multimodal retrieval and generation.
- Automated Knowledge Integration & Corpus Construction: Supports multi-format document parsing and chunked indexing, seamlessly integrating MinerU for easy construction of personalized knowledge bases.
- Unified Build & Evaluate RAG Workflows: Compatible with multiple retrieval and generation inference engines, providing a standardized evaluation system with full-chain visual analysis, achieving a unified process from model invocation to result verification.
Native Multimodal Support
Previously, multimodal RAG often relied on multiple independent tools: text tasks and visual tasks belonged to different workflows, requiring researchers to switch between feature extraction, retrieval, generation, and evaluation tools, with inconsistent interfaces and difficult reproducibility.
UltraRAG 2.1 systematically integrates the multimodal RAG pipeline. All core Servers — Retriever, Generation, and Evaluation — now natively support multimodal tasks and can flexibly connect to various visual, text, or cross-modal models. Researchers can freely orchestrate their own multimodal pipelines within the unified framework — whether for document QA, image-text retrieval, or cross-modal generation — all achievable with minimal effort for end-to-end integration. Additionally, the framework's built-in Benchmarks cover various tasks including visual QA, with a unified evaluation system for researchers to quickly conduct and compare multimodal experiments.
Building on this, UltraRAG 2.1 introduces the VisRAG Pipeline, enabling a complete closed-loop from local PDF indexing to multimodal retrieval and generation. This feature is based on the research in "VisRAG: Vision-based Retrieval-augmented Generation on Multi-modality Documents," which proposes a vision-enhanced retrieval-augmented generation framework for multimodal documents. By jointly modeling document image information (such as charts, formulas, layout structures) with text content, it significantly improves content understanding and QA capabilities for complex scientific documents. UltraRAG integrates this approach, enabling researchers to reproduce VisRAG experiments directly on real PDF document scenarios and further extend multimodal retrieval-generation research and applications.
Automated Knowledge Integration & Corpus Construction
During RAG development, developers need to repeatedly parse, clean, and chunk materials from different sources. As a result, the RAG construction process is often slowed by trivial engineering details, compressing the space for research innovation.
UltraRAG 2.1's Corpus Server makes all of this simple. Users can import corpora from different sources in one go without writing complex scripts — whether Word documents, e-books, or web archives — all automatically parsed into a unified text format. For PDF parsing, UltraRAG seamlessly integrates MinerU, accurately recognizing complex layouts and multi-column structures for high-fidelity text restoration. For mixed image-text files, it also supports converting PDFs page-by-page to images, making visual layouts part of the knowledge. For chunking strategies, Corpus Server offers multi-granularity options: supporting token-level, sentence-level, and custom rules, enabling fine-grained control of semantic boundaries while naturally adapting to structured text like Markdown.
Through this automated pipeline, Corpus Server modularizes the corpus import, parsing, and chunking process, reducing manual scripting and format adaptation work, enabling knowledge base construction to be directly integrated into the standardized RAG pipeline workflow.
Unified Build & Evaluate RAG Workflows
"Chunking, indexing, retrieval, generation, evaluation — each step requires different scripts, too cumbersome!" "Every time I change a parameter or switch a model, do I need to rebuild the entire pipeline?" "After the experiment finally runs, how do I keep evaluation results consistent and comparable?"
These questions are frustrations that almost every RAG researcher has experienced. Existing frameworks often provide fragmented and incompatible support for retrieval, model integration, and evaluation, forcing researchers to repeatedly switch between different tools, with every modification potentially triggering a rebuild of the entire experimental chain. UltraRAG 2.1's goal is to make complex workflows clear and unified again.
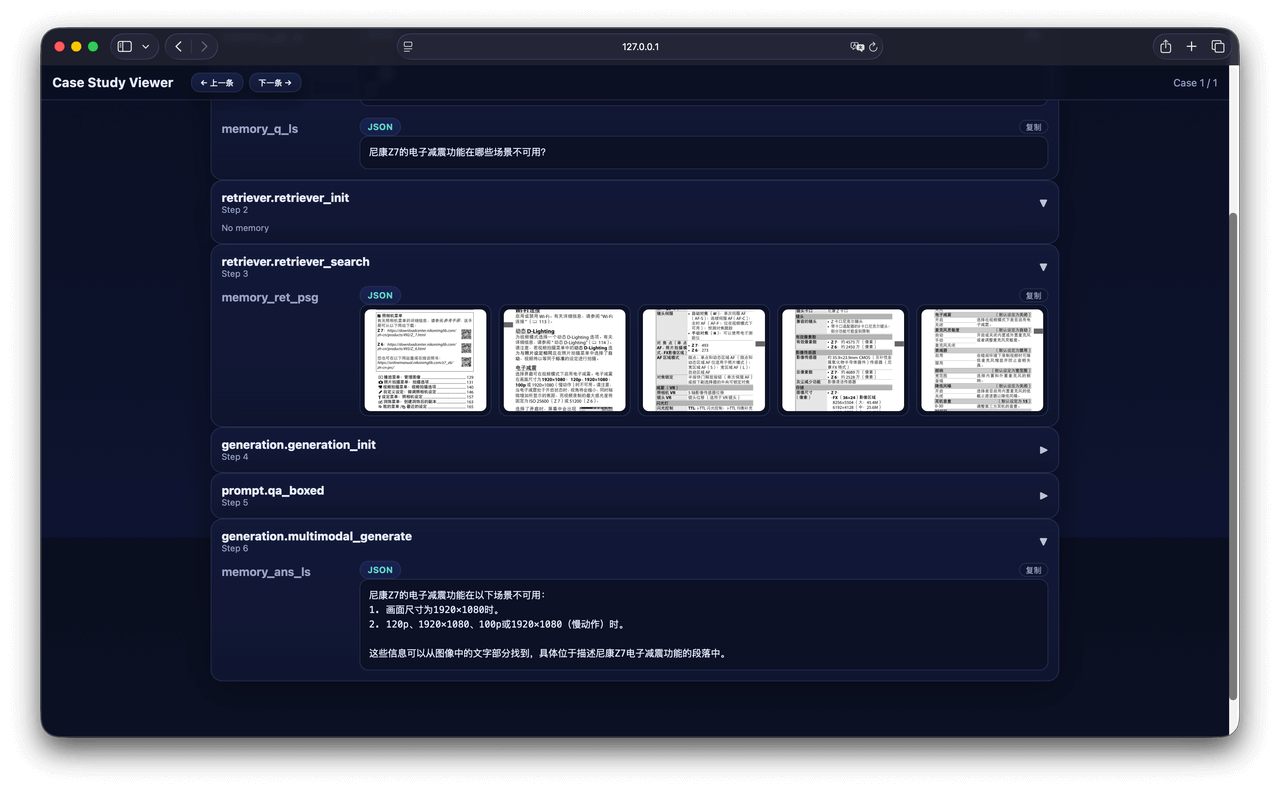
At the retrieval level, the framework supports sparse, dense, hybrid, and multimodal retrieval, compatible with multiple backend engines including Infinity, Sentence-Transformers, and OpenAI. Researchers can freely combine retrieval strategies and models for flexible pipeline design. For model generation, UltraRAG 2.1 simultaneously supports vLLM offline inference and Hugging Face local debugging, while maintaining full compatibility with the OpenAI interface, making model switching and deployment require no code changes. For evaluation, UltraRAG builds a unified Evaluation Server that can compute metrics like ACC and ROUGE for generated results, and supports TREC evaluation and significance analysis for retrieval results. Combined with the visual Case Study UI, researchers can intuitively compare the performance of different models and strategies, making "debugging" truly become "understanding."
Furthermore, UltraRAG achieves full-chain integration from data import to retrieval, generation, and evaluation through a YAML configuration-driven workflow mechanism. Researchers only need to write minimal configuration files to quickly define and reproduce experimental workflows.